

Pour ses 20 ans, Ruby se voit offrir une release majeure, la 2.0.
Notre langage préféré n’a pas pris une ride, au contraire il gagne en maturité.
Le point le plus important au delà des évolutions du langage est que Ruby 2 est compatible avec Ruby 1.9.
Cela va grandement faciliter le passage de l’un à l’autre. Rails 4 est d’ailleurs d’ores et déjà compatible avec Ruby 2.
En comparaison des autres langages, le nombre de gems disponibles et la croissance associée sont assez impressionnants.
Seul node semble être plus dynamique actuellement.
Attention le nombre de modules disponibles ne présume en rien de la qualité intrinsèque du langage.
Mais cela demeure quand même le gage, pour ceux qui en douterait encore, que Ruby n’est pas une voie de garage.
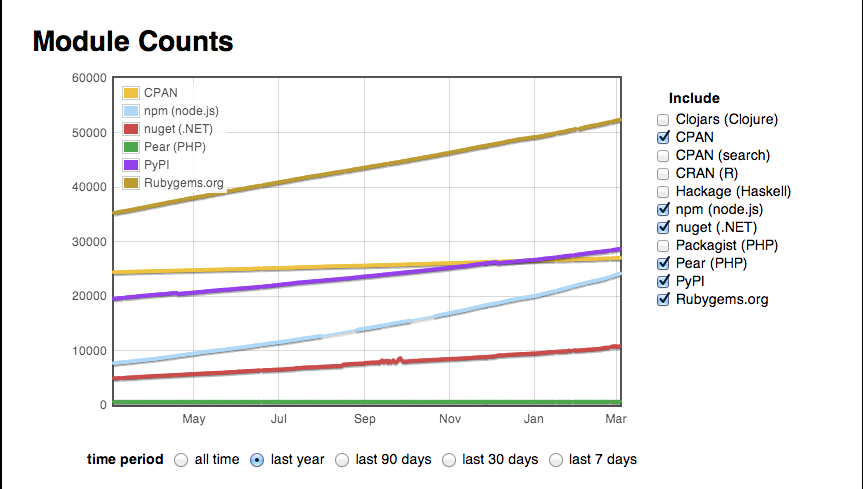
Par contre l’encéphalogramme de PHP semble vraiment très plat </troll>.
Il est rare en Ruby d’avoir des méthodes avec un grand nombre d’arguments, et ceci par soucis de lisibilité et de cohérence (inutile de se soucier de l’ordre des paramètres).
Dans le cas où un grand nombre de valeurs doivent être passées on utilise un Hash.
Rails en fait d’ailleurs grand usage par le biais de sa méthode extract_options!,
qui permet d’extraire les hash.
L’inconvénient est que la définition de la méthode offre peu de visibilité sur ce qu’elle va avoir à traiter.
Les paramètres nommés existent déjà en Objective-C, et par conséquent cela a été repris dans l’implémentation de RubyMotion.
Cette fonctionnalité existe maintenant dans Ruby 2.
On peut donc définir des méthodes de la sorte:
def debug(content, *values, verbose: false)
end
L’inconvénient est qu’une valeur par défaut doit obligatoirement être fournie pour les paramètres nommés. Cela ne devrait toutefois plus être le cas dans les prochaines versions de Ruby.
De même si on passe un argument qui n’est pas inclus dans la définition
on aura un ArgumentError.
debug('foo', debug: true)
# ArgumentError: unknown keyword: debug
Il existe toutefois un moyen de palier à cela en utilisant la notation **.
def debug(content, *values, verbose: false, **extras)
end
À noter également qu’il est possible de faire des choses très avancées dans les paramètres, à savoir définir un paramètre qui utilise la valeur d’un autre ou encore appeler une méthode pour initialiser la valeur par défaut d’un paramètre.
Ex:
def debug(a1 = '', a2 = a1.split, verbose: defaults, **extras)
end
def defaults
false
end
debug "2.0.0"
a1 = 2.0.0
a2 = ["2", "0", "0"]
Vous avez sûrement l’habitude de créer des tableaux de mots avec %w:
%w(foo bar baz)
=> ["foo", "bar", "baz"]
On peut désormais faire la même chose avec des symboles avec %i ou %I:
%i(foo bar baz)
=> [:foo, :bar, :baz]
UTF-8 est maintenant utilisé de base, il n’y a plus lieu de le spécifier en haut de ses fichiers dès lors que l’on utilise quelques caractères exotiques (latin, unicode…).
Depuis 1.9 l’interpréteur offre des warning sur les variables non utilisées.
Généralement le moyen de l’éviter est d’utiliser _.
Par exemple:
{ a: 1, b:2, c:3 }.each do |_, v|
puts v
end
Maintenant il est aussi possible de préfixer n’importe quelle variable avec _
pour éviter les warning.
{ a: 1, b:2, c:3 }.each do |_k, v|
puts v
end
Si vous utilisez rails vous connaissez sûrement prepend_before_filter.
Le prepend va s’assurer d’ajouter le filtre au début de la chaîne d’éxécution.
before_filter :a
prepend_before_filter :b
# b sera appelé avant a
Le prepend introduit dans Ruby 2 a la même vocation. Il va vous permettre de vous assurer que votre inclusion a lieu au début de la chaîne d’éxécution.
En toute logique vous disposez d’un callback dans le module lorsqu’il est prepend.
module Bar
def self.prepended(base)
puts "Prepended."
end
def self.included(base)
puts "Included."
end
end
class Foo
prepend Bar
end
puts Foo.ancestors.join(', ')
class Baz
include Bar
end
puts Baz.ancestors.join(', ')
# Prepended.
# Bar, Foo, Object, Kernel, BasicObject
# Included.
# Baz, Bar, Object, Kernel, BasicObject
Les refinements sont selon moi une vraie killer feature.
La grande promesse des refinements est de limiter voire éviter le monkey patching.
Lorsqu’on commence à goûter à la puissance de Ruby on est très friand de ré-ouvrir des classes au runtime et d’ajouter des méthodes à la volée dans des core classes.
Avec l’expérience c’est une tâche que l’on essaie d’éviter au maximum car cela n’offre aucune garantie.
N’importe qui peut avoir fait la même chose dans une lib, c’est à dire (re-)définir une méthode avec le même nom et écraser la votre.
L’objectif des refinements est de pouvoir limiter la portée d’un ajout et surtout l’obliger de manière explicite ; là ou une inclusion classique aurait une portée globale. Toutefois nous allons voir que cet objectif n’est pas réellement atteint.
module ExtendString
refine String do
def words
self.scan(/[[:alnum:]]+/)
end
end
end
puts "Le petit chaperon rouge.".words.count
# undefined method `words' for "Le petit chaperon rouge.":String (NoMethodError)
module ExtendString
refine String do
def words
self.scan(/[[:alnum:]]+/)
end
end
end
using ExtendString
puts "Le petit chaperon rouge.".words.count
# 4
Contrairement à ce qu’on peut parfois lire,
using n’est pas utilisable à l’heure actuelle dans le contexte d’une classe ou d’un module (undefined method using).
Selon moi cela limite beaucoup son intérêt, puisqu’on ne pourra plus limiter finement sa portée. On n’aura que 2 états, avant et après using.
Toutefois, il faut intégrer que le statut des refinements est expérimental et que l’API peut changer.
Son usage est d’ailleurs actuellement déconseillé. Vous aurez un «warning: Refinements are experimental, and the behavior may change in future versions of Ruby!», sans même utiliser l’interpréteur avec -w.
Si vous trouviez aussi que File.dirname(__FILE__) n’était pas spécialement élégant,
cela tombe bien on a maintenant __dir__.
Par contre je trouve dommage d’avoir une casse différente pour les deux.
Ruby possède maintenant une méthode pour rechercher une valeur dans un tableau trié.
Il s’agit d’une simple méthode dichotomique qui va donc couper le tableau en deux et comparer la valeur avec la valeur du milieu du tableau.
Selon le résultat, si non trouvé, la recherche se poursuit dans la moitié inférieure ou supérieure.
(1..10_000_000).to_a.bsearch { |v| v > 387 }
# => 388
Struct.new(:foo).new('bar').to_h
# => {:foo=>"bar"}
À noter que ce n’est pas disponible pour toutes les classes, ce qui semble logique, étant donné que Ruby ne peut pas deviner comment vous voudriez transformer un Array en Hash par exemple.
to_h est disponible pour Struct, OpenStruct et nil.
L’intérêt d’un énumérateur lazy c’est que l’ensemble de la chaîne de méthode sera interprétée à chaque tour de boucle:
(1..Float::INFINITY).lazy.select { |i| i * i if i.even? }.first(5)
C’est très pratique pour d’énormes volumes de données car cela évite de se retrouver avec des tableaux intermédiaires.
Surtout dans ce cas présent où la borne supérieure est infinie donc la création du tableau l’est également et que par conséquent l’interpréteur planterait sans lazy.
À noter toutefois qu’il ne convient pas d’utiliser lazy à toutes les sauces, sur des tableaux de données
réduits lazy sera beaucoup plus lent que l’implémentation sans.
Dans le cas d’un debug il est souvent pratique d’avoir un aperçu de la chaine d’éxécution.
Retrouver la méthode appelante est très pratique pour cela. Précédemment en Ruby ce n’était pas très fiable et particulièrement lent.
caller_locations vous permet d’obtenir le nom du fichier, la ligne et le contexte appelant.
class A
def hi
puts caller_locations
puts "Hi called by #{caller_locations(1,1)[0].label}"
hello
end
def hello
puts "Hello called by #{caller_locations(1,1)[0].label}"
end
end
A.new.hi
# test.rb:70:in `<main>'
# Hi called by <main>
# Hello called by hi
Je n’ai pas encore eu l’occasion de benchmarker directement Ruby 2.0 en comparaison avec 1.9.
De profonds changements sont annoncés au niveau du garbage collector, du mécanisme de fork mais je préfère tester avant de vous en parler.
Ruby-build possède une formule prête à l’emploi.
J’ai vu passer quelques messages de personnes ayant eu des soucis avec openssl, mais je dois dire que je n’en ai rencontré aucun sur les différentes machines ou je l’ai installé (uniquement Mac).
Cette version s’annonce comme un très bon cru, qui plus est «quasiment» utilisable en l’état. Alors n’attendez plus, à vos claviers !
L’équipe Synbioz.
Libres d’être ensemble.