

L’idée est de déporter la gestion des paramètres protégés du modèle vers le contrôleur.
Cela a du sens dans la mesure où l’autorisation ou non d’écrire un champ est très largement liée au contexte d’exécution (qui suis je, où…).
L’inconvénient est que cela risque de nous amener à écrire plus de code, ce à quoi nous ne sommes pas vraiment habitués.
La suppression des attr_accessible ou attr_protected risque d’être un peu déroutante, dans la mesure ou nous n’aurons pas de protection «par défaut» sur les modèles.
Un exemple de ce qu’il sera possible de faire:
class User < ActiveRecord::Base
include ActiveModel::ForbiddenAttributesProtection
end
class UsersController
def create
@user = User.create(user_parameters)
end
private
def user_parameters
if current_user.admin?
params.require(:user).permit(:firstname, :lastname, :admin)
else
params.require(:user).permit(:firstname, :lastname)
end
end
end
L’inclusion de ActiveModel::ForbiddenAttributesProtection permet
de garantir que du code tel que:
user = User.create(params[:user])
ne fonctionnera plus. Sans cela les deux versions fonctionneraient.
À noter que strong_parameters est utilisable en tant que Gem dans
des projets rails 3.
Le principe est d’éviter de recharger l’intégralité d’une page lorsque l’on suit un lien.
Le mécanisme de base est le même que pjax, c’est à dire AJAX + pushState prévu dans HTML5.
Cela signifie que l’on exécute des requêtes asynchrones mais que l’historique est mis à jour ce qui autorise l’usage des boutons du navigateur tel que le retour à la page précédente.
Le postulat de départ est que les ressources type javascript ou CSS ne changent pas d’une page à l’autre et que l’on peut donc éviter d’avoir à les recharger.
Pour cela Turbolinks va donc aller récupérer le contenu de la page, mettre à jour les meta et autre title et changer uniquement le body.
De même si vous enregistrez vos événements manuellement après que le DOM soit prêt cela ne fonctionnera pas, car l’évènement dom:loaded n’est plus envoyé.
Turbolinks offre un mécanisme de substitution en envoyant ses propres évènements,
tel que page:fetch (pour lancer le chargement), page:load (la page a été renvoyée par le serveur),
page:restore (la page a été rechargée depuis le cache), page:change (la page a été remplacée par
la nouvelle version).
Comme pour une Single Page Application, il faudra également faire attention à éviter les fuites mémoires.
L’avantage de Turbolinks est de se dégrader correctement, en effet l’application fonctionnera tout aussi bien sans, cela n’entrave pas la navigation.
Ce qui signifie qu’il n’y a pas de problème potentiel non plus pour votre référencement.
Un contrôleur peut maintenant inclure ActionController::Live.
Cela lui permet d’émettre une réponse sous forme d’un stream, plutôt que d’un fichier complet à interpréter ou télécharger.
Les méthodes utilisées sont response.stream.write et response.stream.close.
L’avantage est de pouvoir envoyer une réponse morcelée et potentiellement interprétable plus tôt par le navigateur.
Pour exploiter au mieux le potentiel de streaming il vaut mieux utiliser un serveur adapté comme puma, rainbows ou thin.
Le souci avec Unicorn est qu’il ferme la connexion après 30 secondes, son objectif étant de livrer la réponse le plus vite possible, ce qui n’est pas adapté pour du stream.
Dans la logique REST, PUT concerne une modification sur l’intégralité de l’objet. C’est à dire que le formulaire devrait soumettre tous les attributs.
Une modification partielle d’objet doit normalement être effectué avec PATCH.
Comme les navigateurs ne supportent pas plus nativement PATCH que PUT et DELETE,
la méthode traditionnelle sera utilisée, à savoir _method=patch.
PATCH devriendra l’usage par défaut pour les objets en modification mais PUT continuera de fonctionner.
Model.all sera désormais considéré comme un scope et ne retournera plus les enregistrements.
C’est tout à fait logique et c’est déjà comme ça que c’est fait avec mongoid,
qui retourne Mongoid::Criteria, comme pour un scope.
Pour ActiveRecord, c’est ActiveRecord::Relation qui sera retourné.
Pour avoir directement les entités un Model.to_a fera l’affaire.
None est un scope à part entière qui ne retourne aucun résultat. Je n’ai jamais eu de cas ou je souhaitais utiliser des scope qui ne retourne rien, donc j’ai du mal à en voir l’intérêt.
Si vous avez des cas d’usages, dites le moi en commentaire.
L’appel à first et last fera explicitement un tri sur id, plutôt
que de laisser le choix à votre SGBD.
À noter que si un default_scope est utilisé c’est bien lui qui sera pris en compte.
Le pipeline a été déporté du cœur de Rails, pour évoluer de façon autonome.
sprocket-rails évolue donc à un rythme plus soutenu, en calant sa fréquence sur celle de sprocket et en adoptant le même versionning.
Étant disponible en tant que gem, le réglage config.assets.enabled a été retiré.
Pour ne pas utiliser le pipeline il suffit de ne pas utiliser la gem.
Les dossiers de cache ont été séparés par environnement, ce qui va nous simplifier la vie concernant les tests d’intégration.
La précompilation a été revue et très largement améliorée en terme de temps de traitement. Sur les premières démo on parle d’un facteur 5. À confirmer à l’usage.
À noter que la version 3 de sprocket-rails devrait voir l’arrivée de source maps, qui permet de faire concorder un asset original avec sa version minifiée, ce qui offre le meilleur des 2 mondes: un code maintenable, débugable et dont l’accès à la doc est simplifié tout en ayant la performance apportée par la minification.
Cette version devrait concorder avec la sortie de Rails 4.1.
On l’a vu à plusieurs reprises la tendance générale est à l’explicite dans Ruby on Rails.
Le principe est conservé pour references.
En rails 3 includes est utilisé pour éviter les requêtes n+1.
Cela a pour effet de générer 2 requêtes SQL:
Post.includes(:comments)
SELECT "posts".* FROM "posts"
SELECT "comments".* FROM "comments" WHERE "comments"."post_id" IN (1)
En rails 4 cela ne fonctionnera pas si vous précisez des conditions de requêtes via une string, car Rails ne sait pas quel objet vous décrivez dans ce cas.
Par exemple:
Post.includes(:comments).where("comments.created_at > ?", Date.yesterday)
ne fonctionnera pas car une jointure n’est pas faite automatiquement avec comments. Vous devrez le spécifier via:
Post.includes(:comments).where("comments.created_at > ?", Date.yesterday).references(:comments)
À ce moment ce ne sont plus 2 requêtes qui seront exécutées mais 1 seule avec un OUTER JOIN.
Par contre si vous utilisez des requêtes simples ou des symboles, Rails saura se débrouiller seul.
Ex:
Post.includes(:comments).where(:comments => { :email => '' })
Post.includes(:comments).order("comments.created_at")
En rails 3, tout code dynamique entrainait le besoin d’encadrer son scope dans une lambda, afin d’éviter que l’interprétation se fasse au runtime.
Désormais pour éviter toute confusion, tout scope devra être enrobé, même s’il n’y a pas de risque de confusion comme par exemple:
class User
scope :active, where(active: true)
end
deviendra:
class User
scope :active, -> { where(active: true) }
end
À l’image de update_attributes, update_columns fait
son apparition et sera le pendant de update_column.
Voici un petit mémo sur qui fait quoi:
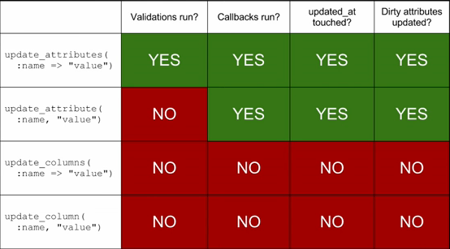
Le update_attribute est souvent utilisé sans savoir qu’il ne joue pas les validations.
De même les update_attribute(s) mettent à jour les dirty attributes, c’est à dire ceux dont la valeur a changé entre temps.
Ex:
u = User.first
u.firstname = "John"
u.update_attributes lastname: "Doe"
entraine:
UPDATE "users" SET "firstname" = 'John', "lastname" = 'Doe', "updated_at" = '2013-01-08 09:09:21.050217' WHERE "users"."id" = 2
La recommandation est de ne plus utiliser update_attribute, qui est en passe d’être
déprécié.
C’est une situation assez compliquée. Logiquement si on fait le choix d’avoir
update_column et update_columns, il n’y a pas de raison de retirer update_attribute.
Pour beaucoup son retrait aurait entrainé du code cassé lors de la mise à jour.
En le gardant et en faisant en sorte que son comportement soit le même que update_attributes,
on risque aussi de casser du code mais de façon beaucoup plus critique car silencieuse.
Pourtant je suis surpris que le choix n’est pas été fait d’homogénéiser l’API. Le passage à une nouvelle version majeure aurait été une bonne occasion.
En résumé on vous conseille de ne plus l’utiliser mais rien ne change si vous choisissez de le faire quand même.
Les plugins n’étaient plus guère utilisé en Rails 3. Ils laissent donc définitivement leur place au profit des gems.
Le find ne disparait pas en tant que tel, mais plutôt l’utilisation de symboles associés, comme find(:first), find(:last), find(:all).
Des méthodes étant prévues au niveau modèle, autant rester DRY.
Les finder dynamiques sont par contre retirés aux dépens du where. C’est à dire:
Je ne suis par contre pas très fan de la méthode de substitution pour les
initialize, à savoir where(…).first_or_initialize.
Qui n’a jamais vu cette erreur ?
RuntimeError: Called id for nil, which would mistakenly be 4 -- if you really wanted the id of nil, use object_id
Celle ci vient du fait que 4 est l’object_id de nil. Rails vous prévient que vous vous êtes peut être trompé en appelant id à la place de object_id.
Désormais vous aurez toujours l’erreur mais elle sera affichée différemment,
avec un simple NoMethodError: undefined method id for nil:NilClass, comme
pour n’importe quelle autre méthode.
C’est logique car il est relativement rare d’avoir à utiliser les object_id dans son application.
Les mécanismes pour mettre en cache une page ou une action sont retirés.
Seuls les caches de fragments sont maintenus. Ces caches seront nommés grâce au hash de leur contenu, ce qui permettra de les faire expirer automatiquement si leur contenu change (puisque leur nom changera également).
Cela permet également de gérer des caches imbriqués de façon transparente.
Fini donc le versionning de cache manuel et fastidieux, tel que:
<% cache "v1", object do %>
<% end %>
La gestion se fait maintenant de manière beaucoup plus simple et automatisée:
<% cache object do %>
<% end %>
En rails 3, le token est automatiquement ajouté par Ruby on Rails dans les formulaires ou les liens qui lient vers des contenu non GET.
Si le token n’est pas présent rails.js se chargeait de l’ajouter.
Ce ne sera plus le cas pour les formulaire soumis en AJAX (remote: true).
En effet la police de sécurité fait qu’il n’est pas possible de soumettre un formulaire en AJAX de depuis un autre domaine, ce qui permet d’éviter cette vérification dans le cas de requêtes de ce type.
Cela permet également de mettre en cache les formulaires. Il y a toutefois un inconvénient qui n’est pas neutre, les formulaires ne fonctionneront plus en l’état pour ceux n’ayant pas activé JavaScript.
Pour forcer l’inclusion d’un token l’option authenticity_token: true peut
être utilisée.
Rails.queue était un peu la grosse nouveauté mise en avant pour Rails 4.
Elle a finalement été retirée et ne sera pas incluse dans cette release.
Cela serait dû à des questions restées pour le moment sans réponse concernant le design de l’API de queue.
Le retrait est d’autant plus dommage qu’il se fait tardivement. Toujours est il que la question reste ouverte, la volonté est toujours affichée d’intégrer un mécanisme de queue dans Rails, mais pas sans une API consistante.
Rails 4 nécessitera Ruby 1.9.3 pour fonctionner.
En rails 4 la plupart des choses qui changent et vont être retirées sont juste dépréciées. Elles seront effectivement retirées en 4.1.
Sur une application récente et avec une bonne couverture de tests, la migration ne devrait pas s’avérer trop complexe.
Sur une application plus ancienne (type rails 2) je ne saurai trop vous conseiller de générer un squelette d’application en rails 4 et d’y migrer votre code progressivement.
À mon goût la sortie de Rails 4 est moins excitante que celle de Rails 2 et 3.
La tête de gondole qu’était le système de queue a été retiré et la plupart des choses présentées sont des consolidations. Ce qui est très bien, mais pas forcément très enthousiasmant.
Par ailleurs la tendance est clairement à l’explicite. Quand il s’agit de sécurité c’est bien sûr indispensable et je pense que la vulnérabilité dévoilée sur Github aura été un des facteurs déclenchant pour revoir le système de mise à jour des objets.
En clair Ruby on Rails est entrain de devenir un framework très puissant, dont la volonté est d’intégrer les dernières possibilités offertes par le web.
Son histoire liée à celle de basecamp est un énorme avantage. La refonte de ce dernier, basecamp next, aura permis d’apporter son lot de bonnes idées à Rails, notamment en terme de performances.
Je vous avez fait part de mes inquiétudes à ce sujet et force est de constater que les choses vont dans le bon sens.
L’équipe Synbioz.
Libres d’être ensemble.
