

Nous avons vu, dans des articles précédents, comment réaliser des single page applications avec Backbone.js ou Ember.js et Rails mais il y a un point que nous n’avons pas encore abordé : le référencement.
En effet, lorsque vous utilisez Backbone.js, Ember.js ou même AngularJS, le contenu de votre page (ou au moins une partie) est chargé via des fonctions JavaScript et des appels AJAX. La principale conséquence de ceci est que les robots, qui viennent crawler vos pages et sont incapables d’exécuter JavaScript, ne voient pas le même contenu qu’un utilisateur lambda utilisant un navigateur web avec JavaScript. Les robots ne voyant pas le contenu complet des pages, ces dernières ne sont pas bien référencées.
Afin de pallier à ce problème il existe plusieurs solutions. La première est de dupliquer toutes les pages de votre site afin de les avoir en HTML et en JS via le framework JavaScript utilisé. Cette solution est lourde, on fait en quelque sorte le double de travail…
Une autre solution est de rendre les pages en HTML au préalable et de les garder en mémoire pour qu’elles soient rendues lorsque les robots parcourent votre site. Il existe plusieurs outils pour vous faciliter la tâche avec cette dernière solution, nous allons en voir quelques-uns ici.
Dans l’optique d’améliorer la navigation des utilisateurs et la rendre plus fluide, les navigateurs récents permettent, via l’attribut rel de la balise <link>, de pré-rendre un contenu avant même que l’utilisateur ne l’ait demandé. En effet, alors que l’utilisateur est sur une page de votre site, vous pouvez indiquer au navigateur de charger le contenu présent à une URL donnée (images, fichiers CSS, contenu HTML…) via la directive suivante :
<link rel="prerender" href="http://www.synbioz.com/blog">
Attention, seuls les navigateurs les plus récents supportent correctement cette directive (IE11+ et Google Chrome 17+).
Lorsque le navigateur va rencontrer cette directive, il va charger le contenu indiqué (cela se fait en arrière plan, pour l’utilisateur cela ne change rien) afin de le mettre en cache. Ceci aura pour but de rendre de façon très rapide cette page ou ce contenu mis en cache si l’utilisateur y accède par la suite.
Il existe, en JavaScript, une API permettant de connaître l’état du rendu de la page : PageVisibility. Celle-ci vous permettra de savoir si une page est bien pré-rendue, document.visibilityState doit être égal à prerender.
Attention tout de même, il ne faut pas utiliser cette méthode pour mettre en cache tout et n’importe quoi, il faut que les contenus mis en cache soient choisis intelligemment car le fait d’appeler une URL pour la mettre en cache utilise de la bande passante et fait appel à votre serveur. Si vous mettez en cache de nombreux contenus et que l’utilisateur ne les utilise pas alors vous aurez sollicité votre serveur pour rien.
Afin de ne pas garder en cache trop de pages, IE, pour sa part, ne garde qu’une seule page en cache. De plus, cette page en cache est supprimée si l’utilisateur clique sur un autre lien ou bien si il ne s’y rend pas dans un délai de 5 minutes. Google Chrome, pour sa part, supprime les pages pré-rendues après 30 secondes si l’utilisateur ne se rend pas sur la page en question. Cette liste de conditions de suppression n’est pas exhaustive, il existe d’autres conditions pour qu’une page soit supprimée du cache.
Afin de générer les pages de votre application et des les garder en cache, nous avons testé Prerender.io. Cette solution est payante mais le prix reste très abordable en comparaison d’autres solutions que nous verrons par la suite.
Le principe de cet outil est de vérifier à chaque appel de l’une des pages de votre site si il s’agit d’un robot ou non. Si tel est le cas, alors Prerender.io vérifie si il possède cette page en cache et la rend telle qu’elle est enregistrée en cache si c’est possible.
Si la page n’est pas en cache alors elle est rendue telle que le crawler la verrait sans Prerender.io, c’est-à-dire sans le contenu intégral. Afin de mettre les pages en cache, Prerender.io fait un appel aux URLs que vous lui indiquez via l’interface et utilise PhantomJS pour que le JavaScript soit exécuté. Une fois que le HTML est rendu complètement avec l’intégralité du contenu alors ce HTML est mis en cache et c’est ce dernier qui sera rendu aux crawlers.
Un certain nombre d’exemples sont disponibles sur le site de prerender.io suivant le langage et le framework que vous utilisez. Dans notre cas nous utilisons Backbone.js et Rails donc nous nous servons de la gem prerender_rails :
gem 'prerender_rails'
Ensuite, il suffit de créer un compte (vous pouvez créer un compte gratuit dans un premier temps) sur le site de Prerender.io afin qu’un token vous soit fourni. Une fois que vous possédez ce dernier, il suffit d’ajouter la ligne suivante dans le fichier de configuration correspondant à l’environnement pour lequel vous souhaitez utilisez Prerender.io :
config.middleware.use Rack::Prerender, prerender_token: 'PRERENDER_TOKEN'
Voilà, vous pouvez maintenant utiliser Prerender.io pour votre application. Il vous suffit d’ajouter des URLs dans l’interface de web de l’outil et ensuite de les mettre en cache. Il y a deux solutions pour indiquer les URLs a mettre en cache, la première est de les indiquer une par une, ce qui peut s’avérer long et compliqué à maintenir à jour sur un site contenant plusieurs dizaines de pages. La seconde solution, beaucoup plus pratique, consiste à indiquer l’URL d’un sitemap et Prerender.io va donc ajouter toutes les URLs présentent dans ce sitemap.
Avant de vous lancer sur une application en production (ou même sur un serveur de staging), vous pouvez vouloir voir localement comment cela fonctionne. Si vous souhaitez tester votre application localement, il vous faut d’abord lancer une instance de Prerender.io sur vore poste. Pour cela, il vous suffit de cloner le dépôt de Prerender :
git clone https://github.com/collectiveip/prerender.git
Ensuite, une fois que vous vous situez dans ce répertoire cloné, il faut installer les dépendances via npm :
npm install
Enfin, il ne vous plus qu’à lancer le serveur de Prerender.io en local pour pouvoir faire vos tests par la suite.
node server.js
Maintenant que Prerender.io est présent et lancé sur votre poste, vous allez pouvoir tester ce service et surtout voir à quoi ressemblent vos pages lorsqu’elle sont mise en cache par Prerender. Pour cela, il vous suffit de connaître l’url pour accéder à Prerender.io en local, dans mon cas http://localhost:3000/, et celle pour accéder à l’application que vous souhaitez tester, ici http://localhost:5000/.
Ensuite, si vous souhaitez voir à quoi va ressembler l’une des pages de votre site lorsqu’elle sera crawlée par Prerender pour être mise en cache vous n’avez plus qu’à appeler l’URL suivante : http://localhost:3000/http://localhost:5000/profiles/3 et voilà ce que vous obtenez :
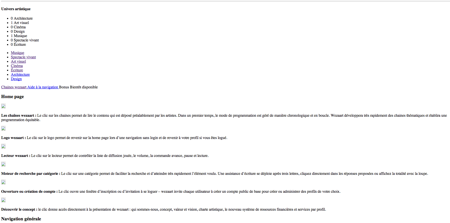
Cela vous permet donc de savoir quelles éléments seront vu par les robots et comment est structuré votre DOM. Vous avez là un outils simple à mettre en place et qui va vous permettre d’améliorer considérablement votre référencement. De plus, le fait de voir la page de votre site telle qu’elle est lors du passage d’un crawler vous permet aussi d’améliorer la structure et la hiérarchisation des éléments du DOM.
Après installation, si vous avez déployé votre application en production avec la configuration nécessaire vous n’avez plus qu’à ajouter les URLS souhaités dans l’interface de Prerender.io. Pour cela vous avez deux solutions, soit indiquer l’URL de chaque page à la main (ça peut être long et difficile à maintenir à jour) ou bien indiquer l’URL d’une sitemap.
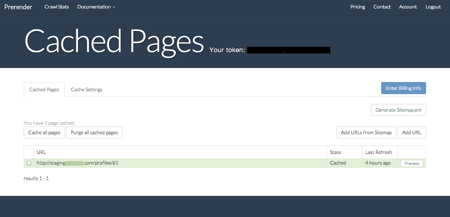
Une fois qu’une page est mise en cache vous pouvez voir ce que le robot verra en cliquant sur le bouton preview :
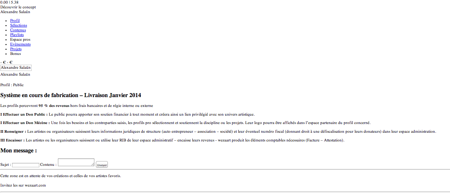
Les robots ne se préoccupent pas du CSS et de l’affichage en lui-même mais de la hiérarchisation des informations dans votre DOM à l’aide des balises HTML. Ici, votre page a bien le bon contenu chargé et non plus les simples appels aux fonctions JavaScript permettant d’afficher le contenu comme c’était le cas avant. Le contenu qui sera référencé sera donc le même que celui vu par l’utilisateur lors de sa navigation.
Nous venons de voir l’un des outils facilitant le référencement de vos single page applications mais il n’en existe pas qu’un et nous allons rapidement voir ce qui existe d’autre.
Brombone fonctionne sur le même principe que Prerender.io, c’est-à-dire qu’il récupère le contenu HTML de toutes les pages de votre site telles qu’un utilisateur lambda les verraient et enregistre le contenu de ces pages à un endroit donné dans le but de le servir quand cela sera nécessaire.
Lorsqu’un robot consulte l’une des pages de votre site préalablement stockée alors c’est ce contenu HTML préalablement enregistré qui est rendu, le robot peut donc voir l’entièreté du contenu de la page.
Cette solution est un petit peu plus onéreuse et ne propose pas de compte gratuit pour pouvoir tester. Brombone fonctionne avec Backbone.js, Ember.js ou encore AngularJS.
Comme les deux exemples précendents, SEO.js rend les pages une première fois pour en sauvagarder le contenu HTML et rendre celui-ci aux robots plutôt que de rendre la page telle qu’elle devrait être rendu sans le JavaScript. Il existe une gem pour Rails afin d’utiliser SEO.js sur le même principe que Prerender.io :
gem 'seojs'
Il suffit ensuite d’ajouter le token fournit par SEO.js pour pouvoir l’utiliser :
Seojs.token = "token"
Il existe bien sûr d’autres outils, cette liste n’est pas exhaustive.
Afin d’avoir un référencement correct sur les moteurs de recherche vous devez faire en sorte que ces derniers puissent accéder au contenu de vos pages au même titre qu’un utilisateur lambda navigant sur votre site.
Avec une single page application ce n’est pas le cas par défaut. Les robots ne voient pas le contenu car celui-ci est chargé de manière asynchrone en JavaScript. De ce fait, votre site n’est pas bien référencé ou en tout cas pas avec le contenu souhaité.
Pour améliorer cela il vous faut permettre aux robots d’accéder à des pages HTML intégralement chargées pour qu’ils parcourent correctement celles-ci et les référencent. Nous avons donc vu ici qu’ils existaient des outils permettant de pré-générer ces pages et de les garder en mémoire pour les servir aux robots lors de leur passage.
Ces outils, bien que payants, sont très pratiques car ils évitent aux développeurs de générer toutes les pages de leurs sites dans deux formats, l’un utilisant JavaScript pour la single page application et l’autre entièrement en HTML et sans chargement asynchrone afin que la page soit intégralement chargée lors du passage du crawler.
Nous avons vu ici deux solutions pour permettre aux robots de crawler votre site avec l’entièreté du contenu HTML lorsque vous utilisez un framework JavaScript. Cependant, ne pas avoir de contenu alternatif à proposer peut également poser problème aux utilisateurs n’ayant pas JavaScript activé.
Faire le choix de ne pas proposer de contenu pour un utilisateur sans JavaScript doit donc être réfléchi et maîtrisé. Certains utilisateurs désactivent JavaScript par choix ou bien ont des navigateurs trop anciens.
N’ayant pas encore utilisé l’un de ces outils sur une application en production, si vous avez pu tester l’un d’eux n’hésitez pas à faire part de votre retour d’expérience. Idem si vous avez préféré dupliquer vos pages pour les rendre en HTML sans passer par un framework JavaScript.
L’équipe Synbioz.
Libres d’être ensemble.