

Lecteur aguerri, vous devez savoir que nous sommes, chez Synbioz, une bande de Ruby Lovers comme tant d’autres !
Au cœur de notre activité quotidienne réside Ruby, aussi nous prenons un certain plaisir à le découvrir et le redécouvrir autant que possible !
C’est pourquoi nous parlerons aujourd’hui magie noire, mysticisme voire de l’Histoire qui a fait le mythe. Vous l’aurez deviné, nous allons parler de Rake.

Sans complètement paraphraser la documentation officielle de Ruby on Rails, Rake est un utilitaire qui s’inspire de Make — disponible dans l’écosystème Unix depuis 1976 grâce à Stuart Feldman.
Rake tire son origine de feu Jim Weirich, dont la première Release remonte à avril 2007. Rake est ainsi l’équivalent de Make écrit en Ruby et pour Ruby, pour le plus grand bonheur des rubyistes !
Tout comme Make et les Makefiles, Rake utilise des Rakefiles pour définir une liste de tâches. Dans le contexte de Ruby on Rails, Rake est surtout utilisé à des fins administratives, en témoignent les tâches de migration de base de données ou la tâche spécifique à l’affichage de toutes les routes que nous verrons plus loin dans cet article. Mais il est possible d’étendre beaucoup plus loin son utilisation — dans le contexte de la métaprogrammation par exemple.
Vous l’aurez compris, Rake est un utilitaire formidable et indispensable de par son implémentation comme pour sa flexibilité et son aisance d’utilisation.
D’ailleurs, Rake est un projet Open Source dont le code est disponible sur Github.
Dans un premier temps, nous allons voir comment utiliser Rake avec Ruby. Puis nous verrons comment il s’intègre parfaitement dans le contexte de Ruby on Rails.
Puisqu’il me parait impossible de shunter le fameux Hello World!, créons-le avec Rake !
NB : N’oubliez pas d’installer Ruby avant tout, car Ruby c’est la vie !
Premièrement, faites-vous un petit répertoire de test et créez deux fichiers ;
l’un Gemfile qui va nous permettre d’installer Rake,
puis l’autre Rakefile qui contiendra notre tâche.
# Gemfile
source 'https://rubygems.org'
gem "rake"
# Rakefile
desc "Afficher Hello World"
task :say_hello do
puts "Hello World!!!"
end
Il nous faut enfin installer Rake depuis notre terminal en nous plaçant dans notre répertoire et en lançant la commande suivante :
$ bundle install
Maintenant que le plus dur est derrière nous, il nous suffit simplement de lancer notre tâche pour afficher le résultat :
$ rake say_hello
=> Hello World!!!
Et voilà ! Nous venons d’afficher Hello World!!! en interprétant le code Ruby contenu dans notre tâche. Présentement, vous êtes en mesure d’imaginer toutes les possibilités liées à l’utilisation de Rake avec Ruby, du simple affichage de texte à la création d’un setup complet pour vos projets et bien plus encore…
Rake s’utilise principalement en ligne de commande comme la commande rails par
exemple.
Et comme toute commande dans l’écosystème Unix,
il est possible d’en afficher toutes les possibilités d’utilisation.
Pour ce faire, il suffit de lancer la commande rake -T dans votre terminal
favori.
Vous retrouverez ainsi la liste des commandes par défaut d’un projet Rails mais
aussi les tâches écrites par vos soins, parmi lesquelles :
$ rake -T
=>
rake about # List versions of all Rails frameworks and the environment
rake assets:clean[keep] # Remove old compiled assets
rake assets:environment # Load asset compile environment
rake assets:precompile # Compile all the assets named in config.assets.precompile / Create nondigest versions of all chosen digest assets
rake db:create # Creates the database from DATABASE_URL or config/database.yml for the current RAILS_ENV (use db:create:all to create all databases in th...
rake db:drop # Drops the database from DATABASE_URL or config/database.yml for the current RAILS_ENV (use db:drop:all to drop all databases in the config)
rake db:migrate # Migrate the database (options: VERSION=x, VERBOSE=false, SCOPE=blog)
rake db:rollback # Rolls the schema back to the previous version (specify steps w/ STEP=n)
rake db:schema:load # Load a schema.rb file into the database
rake db:seed # Load the seed data from db/seeds.rb
rake db:setup # Create the database, load the schema, and initialize with the seed data (use db:reset to also drop the database first)
rake test # Runs all tests in test folder
rake test:all # Run tests quickly by merging all types and not resetting db
...
Ok, mais si Rake est fait pour Ruby, comment fonctionne-t-il avec Rails ?
C’est très simple dans les faits.
Tout comme notre exemple précédent, Rails génère un Rakefile qui contient deux
éléments.
Le premier est un simple require du fichier de configuration application.rb qui
est au cœur d’une application Rails.
Le second permet de charger toutes les tâches Rake au démarrage de l’application.
Par défaut, les tâches Rake se trouvent dans le répertoire lib et sont chargées
automatiquement au démarrage de l’application.
Mais ça n’est pas forcément le cas dans toutes les versions de Rails,
alors soyez vigilant·e !
Prenons un exemple tout simple. Imaginons, l’espace d’un instant, que Interpol vous missionne pour créer une application qui liste tous les criminels présents dans la série Doctor Who.
Houla ! Faut-il rentrer chaque criminel un par un dans une interface CRUD ? Pourquoi pas, mais ce serait fastidieux compte tenu des 36 saisons…
Nous allons plutôt opter pour une autre solution. Il nous suffira de récupérer un fichier CSV par exemple qui va nous servir à alimenter la base de données grâce à une tâche Rake !
Nous allons commencer par créer notre nouvelle application Rails que l’on va joliment nommer criminals :
$ rails new criminals
Vous remarquerez dans votre terminal que la génération d’une nouvelle
application crée automatiquement un Rakefile et installe la gem rake comme
expliqué plus haut.
En outre, si vous regardez dans le répertoire lib,
vous verrez qu’il contient déjà un répertoire tasks qui va accueillir nos
différentes tâches Rake.
Notre application étant totalement vierge, il nous faut créer tout un contexte propre aux criminels, à savoir un modèle, son contrôleur et les vues.
Pour ce faire, nous emploierons la magie de Rails !
$ rails generate scaffold Criminal name:string episode:integer motivation:string episode_title:string
À ce niveau, Rails a généré une pléthore de fichiers dont l’objectif est de créer un véritable contexte pour nos criminels. Chouette ! Mais c’est bizarre il n’y a rien dans la base de données…
C’est normal ! Autant Rails va nous permettre de générer tous nos contextes et bien plus, autant la migration est un rôle réservé à… Rake bien sûr !
Comme nous avons vu plus haut avec la commande rake -T,
il existe plusieurs commandes par défaut pour Rake.
Ici, notre objectif est de créer la base de données,
puis d’effectuer les migrations de structure (à savoir la création concrète de la
table criminals) et enfin, nous voudrons remplir cette table avec une tâche
custom cette fois-ci.
# Création de la base de données
$ rake db:create
=> Created database 'criminals_development'
# Migration de structure
$ rake db:migrate
=> == 20170927154612 CreateCriminals: migrating ==================================
-- create_table(:criminals)
-> 0.0100s
== 20170927154612 CreateCriminals: migrated (0.0100s) =========================
Voilà comment la magie de l’outil Rake nous permet de construire notre base de données sans aucun clic dans l’exécrable phpMyAdmin (pour ne prendre que cet exemple). En réalité, Rake va nous permettre d’effectuer des opérations en base de données : insertions, altérations, et même de retourner en arrière, et cela en une seule ligne de commande !
Pour information, la commande inverse de rake db:migrate est la commande rollback :
$ rake db:rollback STEP=1
La mention STEP représente chaque itération de migration. On peut voir ça comme
des sauts, des bonds en arrière. Aussi STEP=1 correspond à un saut d’une seule
migration en arrière.
Nous touchons presque au but ! Il nous reste à présent la migration du contenu de notre CSV dans la base de données fraîchement créée.
Nous allons écrire notre première tâche Rake dans le contexte de Rails, excitant non ?
Comme toujours avec Rails, il existe une commande pour générer un fichier destiné à accueillir nos tâches (il est tout à fait possible de le faire manuellement) :
$ rails generate task data
Running via Spring preloader in process 24152
create lib/tasks/data.rake
Cette tâche a tout simplement créé un fichier data.rake dans le répertoire
lib/tasks que nous l’avons vu plus haut.
Ce fichier est pour le moment uniquement doté d’un namespace :
namespace :data do
end
Nous allons maintenant créer la tâche que nous attendons impatiemment depuis le début de cet article !
Tout d’abord, nous traitons un fichier CSV,
il est donc nécessaire d’importer la bibliothèque pour travailler avec ce format en
ajoutant simplement require 'csv' en entête de notre fichier.
Puis, il nous faut créer la tâche en elle-même pour importer nos criminels. Pour ce faire plusieurs solutions sont possibles. Nous nous contenterons d’une solution simple :
# CSV file : lib/data/villains_from_doctor_who.csv
"name","episode","motivation","episode_title"
"Sea Devils","10","Capture the Doctor","The Sea Devils - Warriors of the Deep"
"L1 robot","4","Capture the Doctor","The Mysterious Planet"
...
# data.rake
require 'csv'
namespace :data do
desc "Import all Doctor Who villains from CSV"
task :import_villains do
csv_path = File.join("#{Rails.root}/lib/data/villains_from_doctor_who.csv")
csv_content = File.read(csv_path)
csv = CSV.parse(csv_content, headers: true, header_converters: :symbol, converters: :all)
csv.each do |row|
begin
Criminal.find_or_create_by(row.to_hash)
rescue
# Affiche les erreurs dans le terminal
puts "Error: #{row} will not be loaded"
# Log les erreurs dans les logs d'environnement
Rails.logger.info "Error: #{row} will not be loaded"
# On poursuit l'itération même si une erreur est détectée
next
end
end
end
end
Notre tâche est enfin terminée, reste à lancer la commande et vérifier que tout s’est bien passé.
$ rake data:import_villains --trace
=> ** Invoke data:import_villains (first_time)
** Execute data:import_villains
rake aborted!
NameError: uninitialized constant Criminal
Did you mean? Criminals
Oops, something went wrong!
NB : l’argument --trace va nous permettre de lancer nos commandes de manière
verbeuse.
Ainsi on peut récupérer le cheminement que Rake emprunte pour jouer une tâche,
aussi appelé stacktrace.
Ici on aurait tendance à penser à un problème avec le modèle Criminal mais la
réalité est toute autre…
Méfiez-vous, une tâche Rake a toujours besoin d’un contexte pour s’exécuter.
Et ce contexte est appelé environnement !
Le contexte de l’environnement se passe comme ceci à la tâche :
task import_villains: :environment do
Par défaut, :environment prendra l’environnement courant pour exécuter notre
tâche.
Néanmoins, la magie de Rake nous permet de lancer nos tâches en passant des
arguments.
Pour en savoir plus sur les environnements dans le contexte de Rails,
rendez-vous dans le répertoire config/environnements de votre application.
Rejouons donc notre tâche en spécifiant un environnement de développement et voyons si tout se passe comme il se doit.
$ rake RAILS_ENV=development data:import_villains --trace
=> ** Invoke data:import_villains (first_time)
** Invoke environment (first_time)
** Execute environment
** Execute data:import_villains
Félicitations ! Nous voici donc avec notre liste fraîchement créée !

N’est-ce pas !
Potentiellement, nous pouvons tout faire avec Rake. C’est un outil génialissime qui vous permettra de gérer vos applications avec simplicité et souplesse.
Le saviez-vous, il est tout à fait possible de surcharger les tâches Rake par défaut fournies par Rails. C’est par ailleurs un sujet plusieurs fois traité sur notre blog, comme l’utilisation de Scenic au sein d’un Rails Engine.
Prenons par exemple la tâche rake routes qui nous permet d’afficher toutes les
routes (URI) de notre application.
Bien que très utile cette tâche est souvent indigeste,
surtout dans des projets importants.
C’est pourquoi il est parfois très intéressant de surcharger une tâche existante pour nous simplifier la vie :)
Prenons donc cet exemple de tâche Rake :
# lib/tasks/custom_routes.rake
desc "My own custom routes for Rails"
task custom_routes: :environment do
Rails.application.reload_routes!
routes = Rails.application.routes.routes.to_a
red_color = "\033[1;31m"
blue_color = "\033[1;34m"
routes.group_by { |route| route.defaults[:controller] }.each_value do |group|
puts red_color + "CONTROLLER: #{group.first.defaults[:controller].to_s}" if group.first.defaults[:controller].to_s.present?
group.each do |route|
puts blue_color + "#{route.verb}" + " ||| " + "#{route.defaults[:action]}" + " ||| " + "#{route.name}" if route.name.to_s.present?
end
end
end
Voici comment lancer la commande, ainsi que le résultat en image :
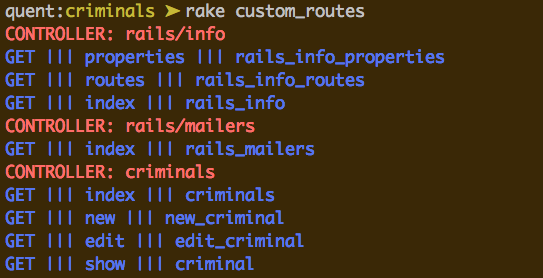
En se baladant un peu sur Github, vous trouverez des projets très chouettes comme routes de Benoit Caccinolo qui vous propose de colorer vos routes dans votre terminal de façon plus élaborée !
Rake n’est pas seulement magique, il est devenu indispensable dans l’écosystème Ruby et Rails !

Pour ma part, je vous invite fortement à utiliser Rake dans vos projets Ruby et Rails, si ça n’est pas déjà le cas. Vous verrez, c’est réellement magique !
Si d’aventure vous avez une utilisation plus complexe de tâches, de gestion de données, d’environnement ou encore de réutilisation de scripts à travers toute votre application… N’hésitez pas, comme moi, à découvrir THOR !
Bien qu’ils ne servent pas les mêmes desseins, ces deux outils semblent correspondre parfaitement aux attentes des développeurs. Par ailleurs, si vous voulez pousser vos recherches sur le sujet, vous vous rendrez compte que Rails se sert de Thor depuis la version 3 et qu’il se cache derrière les commandes Rails !
Me faudra-t-il échanger un bon râteau pour un excellent marteau ?
Telle est la question :)
L’équipe Synbioz.
Libres d’être ensemble.