

Lorsqu’il s’agit de soumettre des requêtes complexes à notre base de données, nous avons une tendance naturelle à aller à la simplicité en passant à ActiveRecord du SQL brut dans une chaîne de caractères. Ce qui donne quelque chose comme ça
Book.where("status > 2").order("title asc")
Cette simplicité est néanmoins toute relative car il est tout de même question de SQL, un langage touffu aux multiples dialectes, spécifiques à chaque SGBD.
Même si de prime abord il peut sembler pertinent de procéder ainsi, il s’avère bien souvent qu’il est plus judicieux de construire sa requête en Ruby. Si vous travaillez sur un projet utilisant le framework Rails, il y a de fortes chances pour que vous utilisiez l’ORM livré en standard : ActiveRecord. Ce dernier repose lui-même sur ARel, une gem qui nous permet d’écrire nos requêtes SQL programmatiquement. Pour cela, ARel construit un arbre syntaxique abstrait (abstract syntax tree, ou AST, en anglais).
Il est facile de confondre les rôles d’ActiveRecord et d’ARel si l’on y prête peu d’attention. Afin de clarifier la portée de chacun, il est nécessaire de comprendre ce qu’est un AST et ce que fait un ORM.
ARel construit un AST. Un arbre donc. Directement issu de la théorie des graphes, avec des branches et des nœuds. À chaque appel à ARel que l’on fait, notre arbre s’étoffe. On y ajoute de nouvelles branches, de nouveaux nœuds, jusqu’à obtenir le résultat attendu. On pourrait schématiser un tel arbre comme ceci :
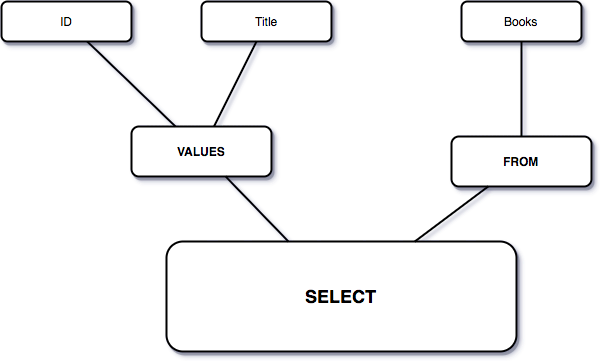
ActiveRecord quant à lui est un ORM. Son rôle n’est pas de construire la requête à proprement parler, car il délègue cette tâche à ARel, mais de soumettre cette dernière à la base de données puis d’en interpréter la réponse pour nous présenter celle-ci sous forme d’objets : les fameux modèles ActiveRecord.
Nous avons donc à disposition ARel pour construire nos requêtes, et ActiveRecord pour communiquer avec notre base de données. Voyons ensemble comment ARel peut nous être utile dans un cas complexe en prenant un exemple.
Des exemples d’utilisation d’ARel, il y en a à foison. Mais de vrais exemples
velus tels qu’on peut en rencontrer en conditions réelles, là tout de suite ça
se fait plus rare ! Quand il s’agit de faire un peu plus que de construire une
clause where que l’on aurait pu faire de manière transparente avec
ActiveRecord, on se retrouve livré à nous-même devant
la documentation d’ARel et
son code source quand celle-ci s’avère
insuffisante.
Pour ceux qui auraient besoin d’une piqûre de rappel ou qui n’auraient pas lu l’article de Nicolas expliquant en quoi ActiveRecord c’est aussi ARel, je leur conseille d’y jeter un œil avant de poursuivre.
Les bases d’ARel ainsi remémorées, attaquons-nous à plus costaud et poussons le dans ses derniers retranchements.
Partons du postulat suivant : Notre base de données modélise une bibliothèque composée de livres, d’auteurs et de genres divers. Certains livres sont lus, d’autres attendent sagement de l’être. Certains sont des romans, d’autres des recueils de nouvelles. Certains sont bien notés, d’autre moins bien… Bref, nous disposons de tout un tas d’informations à leur sujet et nous souhaiterions en extraire des statistiques.
Disons que nous aimerions connaître pour chaque livre lu : son titre, son code ISBN, son auteur, son genre, son format, son nombre de pages et sa note. Nous aimerions aussi avoir des statistiques par auteur : le nombre de livres lus, de pages lues et la note moyenne. Ainsi que des statistiques globales.
Voici à quoi ressembleraient nos modèles ActiveRecord :
class Book < ActiveRecord::Base
belongs_to :author, inverse_of: :books
belongs_to :genre, inverse_of: :books
enum format: %i(novel novella collection)
enum rating: { excellent: 4, good: 3, mediocre: 2, poor: 1 }
enum status: { want_to_read: 0, currently_reading: 1, read: 2 }
validates :title, :author, :genre, :format, :rating, presence: true
validates :isbn, uniqueness: true
validates :pages, numericality: true
end
class Author < ActiveRecord::Base
has_many :books, inverse_of: :author
validates :name, presence: true
end
class Genre < ActiveRecord::Base
has_many :books, inverse_of: :genre
validates :label, presence: true, uniqueness: true
end
Pour l’exercice, commençons simplement par écrire notre requête SQL à la main. Oui, oui, j’ai bien dit notre requête puisque nous verrons qu’il est possible d’extraire toutes les statistiques dont nous avons besoin en une unique requête !
Mais allons-y par étape. Récupérer tous les livres lus, jusque là on sait faire.
SELECT *
FROM books
WHERE status = 2; -- status is read
Remarquons que dans notre modèle Book, le statut est déclaré comme un enum.
Cependant, ActiveRecord ne crée pas de type ENUM en base de données mais
enregistre l’information sous la forme d’un entier, la correspondance étant
faite en Ruby dans le modèle.
Limitons-nous à présent aux champs désirés.
SELECT title, isbn, format, pages, rating
FROM books
WHERE status = 2; -- status is read
À l’aide de jointures, récupérons également le nom de l’auteur et le genre.
SELECT books.title, books.isbn, books.format, books.pages, books.rating,
authors.name, genres.label
FROM books
INNER JOIN authors ON books.author_id = authors.id
INNER JOIN genres ON books.genre_id = genres.id
WHERE books.status = 2; -- status is read
Maintenant ça devient intéressant ! Nous allons utiliser une fonctionnalité
méconnue de la clause GROUP BY. Disponible depuis
PostgreSQL 9.5,
il s’agit des GROUPING SETS et notamment d’une syntaxe raccourcie nommée
ROLLUP.
Le concept est simple, nous définissons plusieurs ensembles de regroupement, ce
qui va nous permettre de récupérer des sous-totaux. Pour vous donner un exemple,
simplifions notre table books pour éviter de s’encombrer de jointures. Voici
les données qu’elle contient :
=> SELECT author, genre, pages FROM books;
author | genre | pages
-----------+---------+-------
Pratchett | SF | 288
Pratchett | Fantasy | 288
Damasio | Fantasy | 1392
Damasio | SF | 492
(4 rows)
À présent, admettons que nous souhaitons connaître le nombre de pages par auteur, mais aussi par genre, ainsi qu’au global. On écrirait alors notre requête comme ceci :
=> SELECT author, genre, sum(pages) FROM books
GROUP BY GROUPING SETS ((author), (genre), ());
author | genre | pages
-----------+---------+-------
Pratchett | | 576
Damasio | | 1884
| SF | 780
| Fantasy | 1620
| | 2460
(5 rows)
Notez la présence du troisième set vide nous permettant d’obtenir le nombre de pages total.
Si nous souhaitons regrouper selon plusieurs critères pour petit à petit élargir nos regroupements jusqu’à obtenir un total de toutes les lignes, nous pouvons écrire quelque chose comme ceci
GROUP BY GROUPING SETS ((author, id), (author), ())
ROLLUP quant à lui est juste un sucre syntaxique nous permettant d’écrire la
même chose ainsi
GROUP BY ROLLUP (author, id)
Voyons ce que donne notre requête avec de tels regroupements.
SELECT MAX("books"."title") AS title,
MAX("books"."isbn") AS isbn,
MAX("books"."format") AS format,
SUM(COALESCE("books"."pages", 0)) AS pages,
CAST(AVG("books"."rating") AS INTEGER) AS rating,
MAX("authors"."name") AS author,
MAX("genres"."label") AS label,
GROUPING("authors"."id", "books"."id") AS rank
FROM "books"
INNER JOIN "authors" ON "authors"."id" = "books"."author_id"
INNER JOIN "genres" ON "genres"."id" = "books"."genre_id"
WHERE ("books"."status" = 2)
GROUP BY ROLLUP( "authors"."id", "books"."id" );
L’on remarque que notre clause SELECT a quelque peu évolué. En effet,
maintenant que nous regroupons nos données, il faut préciser de quelle manière
nous souhaitons agréger les valeurs des colonnes qui ne font pas l’objet de ce
regroupement.
Pour obtenir le nombre de pages de l’ensemble des livres d’un auteur, il va nous
falloir en faire la somme. Attention toutefois, PostgreSQL est pointilleux et
n’apprécie pas de trouver des valeurs nulles parmi celles à additionner. Pour
éviter de le froisser dans le cas où l’on aurait oublié d’indiquer le nombre de
pages d’un livre, nous utilisons la fonction COALESCE pour lui fournir une
valeur par défaut. Ici zéro.
Afin d’obtenir une note moyenne par auteur que l’on puisse interpréter de la
même manière que pour nos livre, nous aurons besoin de manipuler des nombres
entiers. Pour ce faire, PostgreSQL nous permet de forcer le type d’une valeur
grâce à la fonction CAST.
Notez que nous aurions également pu utiliser la syntaxe ::TYPENAME, qui est
plus spécifique à PostgreSQL, de cette manière :
SELECT AVG(books.rating)::INTEGER;
Quand le choix de la valeur importe peu, il faut bien se décider pour l’une
d’entre elles. Ici j’ai décidé de garder la plus grande avec la fonction MAX.
J’aurais tout aussi bien pu prendre la plus petite avec MIN. Voire les agréger
avec STRING_AGG, mais cela n’aurait eu que peu d’intérêt puisque dans le cas
des lignes représentant les statistiques d’un livre, nous n’aurons qu’une valeur
et dans les autres cas, ces valeurs ne nous intéressent pas.
Précisons qu’il n’existe pas de fonction FIRST native, qui nous permettrait de
choisir la première valeur parmi celles dont on dispose, mais qu’il est possible
de créer ses propres fonctions. En voici un exemple :
-- Create a function that always returns the first non-NULL item
CREATE OR REPLACE FUNCTION public.first_agg ( anyelement, anyelement )
RETURNS anyelement LANGUAGE SQL IMMUTABLE STRICT AS $$
SELECT $1;
$$;
-- And then wrap an aggregate around it
CREATE AGGREGATE public.FIRST (
sfunc = public.first_agg,
basetype = anyelement,
stype = anyelement
);
Avec une telle fonction nous aurions pu écrire :
SELECT FIRST(books.isbn) AS isbn;
Une extension à PostgreSQL proposant une version plus optimisée de cette fonction est disponible sur PGXN.
Enfin, pour nous permettre de distinguer les différentes lignes que nous
retournera PostgreSQL, nous ajoutons une colonne supplémentaire indiquant le
niveau de regroupement à l’aide de la fonction GROUPING qui prend les même
arguments que GROUP BY ROLLUP.
Profitons-en pour ajouter une clause de tri pour ordonner nos lignes par auteur, par titre et par rang.
SELECT MAX("books"."title") AS title,
MAX("books"."isbn") AS isbn,
MAX("books"."format") AS format,
SUM(COALESCE("books"."pages", 0)) AS pages,
CAST(AVG("books"."rating") AS INTEGER) AS rating,
MAX("authors"."name") AS author,
MAX("genres"."label") AS label,
GROUPING("authors"."id", "books"."id") AS rank
FROM "books"
INNER JOIN "authors" ON "authors"."id" = "books"."author_id"
INNER JOIN "genres" ON "genres"."id" = "books"."genre_id"
WHERE ("books"."status" = 2)
GROUP BY ROLLUP( "authors"."id", "books"."id" )
ORDER BY author, title, rank;
Nous pourrions nous arrêter ici et demander à ActiveRecord d’exécuter notre requête en l’état.
results = ActiveRecord::Base.connection.execute <<~SQL
SELECT MAX("books"."title") AS title,
MAX("books"."isbn") AS isbn,
MAX("books"."format") AS format,
SUM(COALESCE("books"."pages", 0)) AS pages,
CAST(AVG("books"."rating") AS INTEGER) AS rating,
MAX("authors"."name") AS author,
MAX("genres"."label") AS label,
GROUPING("authors"."id", "books"."id") AS rank
FROM "books"
INNER JOIN "authors" ON "authors"."id" = "books"."author_id"
INNER JOIN "genres" ON "genres"."id" = "books"."genre_id"
WHERE ("books"."status" = 2)
GROUP BY ROLLUP( "authors"."id", "books"."id" )
ORDER BY author, title, rank;
SQL
Mais cette approche est quelque peu indigeste et manque d’intention. On a bien essayé d’apporter une explication au chiffre magique qui représente le statut d’un livre, par le biais d’un commentaire ; mais cela reste insuffisant. Et si demain nous devons relire notre requête, l’adapter à une évolution, en faire une déclinaison, ou changer de système de base de données, ça risque d’être plus compliqué que prévu.
Si en plus notre requête devait être dynamique et accepter des contraintes que nous ne maîtriserions pas (ne comptabiliser que les livres des auteurs dont le nom nous serait spécifié par l’utilisateur, par exemple), alors il nous faudrait être vigilant aux injections SQL.
En tout cela, ARel peut nous être utile. Voyons ensemble comment s’y prendre.
L’un des intérêts d’ARel est de nous permettre de composer notre requête en chaînant des appels de méthodes. Pour ce faire, nous allons créer une classe dont les méthodes astucieusement nommées décriront nos intentions et feront appel aux méthodes fournies par ARel.
Voici à quoi ressemblerait une classe qui nous permettrait de composer nos requêtes à loisir.
class QueryBuilder
attr_reader :query
def initialize(query)
@query = query
end
protected
def reflect(query)
self.class.new(query)
end
end
Cette classe repose sur le design pattern builder. La méthode reflect de
celle-ci crée une nouvelle instance de classe sur base de la requête reçue en
paramètre, ce qui nous permettra de chaîner nos appels par la suite.
Ajoutons-y quelques méthodes qui nous seront utiles par la suite lorsque nous voudrons utiliser ActiveRecord pour consommer l’AST construit grâce à ARel.
class QueryBuilder
attr_reader :query, :visitor
def initialize(query)
@query = query
@visitor = Arel::Table.engine.connection.visitor
end
def where_clause
visitor.compile(context.wheres)
end
def group_clause
visitor.compile(context.groups)
end
protected
def reflect(query)
self.class.new(query)
end
def context
query.ast.cores.last
end
end
Nous avons à présent une classe de base sur laquelle se reposer pour composer n’importe quelle requête. Étendons alors cette classe avec quelques méthodes plus spécifiques à la composition de requêtes dont l’objet est d’extraire des statistiques.
class StatQueryBuilder < QueryBuilder
include Arel::Nodes
# @param field [Arel::Attributes::Attribute] an ARel table field
# @return [Arel::Nodes::Maximum] max value for the given field
def pick_one(field)
field.maximum
end
# @param field [Arel::Attributes::Attribute] an ARel table field
# @param default [Numeric|String] a fallback value for the given field
# @return [Arel::Nodes::NamedFunction] the value of the given field or the
# fallback value if field is null
def coalesce(field, default = 0)
NamedFunction.new("COALESCE", [field, default])
end
# @param field [Arel::Attributes::Attribute] an ARel table field
# @param default [Numeric] a fallback value for the given field
# @return [Arel::Nodes::Sum] the sum of each value for the given field
def safe_sum(field, default = 0)
NamedFunction.new("SUM", [coalesce(field, default)])
end
# @param field [Arel::Attributes::Attribute] an ARel table field
# @return [Arel::Nodes::NamedFunction] the average integer value of field
def round_avg(field)
NamedFunction.new("CAST", [field.average.as("INTEGER")])
end
# @param grouping_elements [Array<Arel::Nodes::GroupingElement>] the fields
# @return [Arel::Nodes::NamedFunction] the grouping rank
def grouping(grouping_elements)
NamedFunction.new("GROUPING", [grouping_elements])
end
# @param grouping_elements [Array<Arel::Nodes::GroupingElement>] the fields
# @return [Arel::Nodes::RollUp] the roll up grouping sets
def grouping_sets(grouping_elements)
RollUp.new(grouping_elements)
end
end
Avec ces quelques méthodes, nous avons en main tous les outils nécessaires pour requêter correctement notre base.
La grande majorité de ces méthodes fait appel à NamedFunction. Cette classe,
mise à notre disposition par ARel, nous permet de créer nos propres fonctions.
ARel ne supportant pas toutes les fonctions de PostgreSQL, c’est ainsi que nous
pallions à ce problème. Notons que les fonctions que nous créons ici
(COALESCE, CAST et GROUPING) ne sont pas spécifiques à PostgreSQL, mais ne
sont pas non plus supportées par tous les systèmes de base de données gérés par
ARel.
Cette fois, ça y est, il est grand temps de construire notre requête ! Pour cela
étendons StatQueryBuilder pour implémenter nos méthodes maison. Souvenez-vous,
celles qui véhiculent de l’intention et que nous pouvons composer à loisir.
class BookStatQueryBuilder < StatQueryBuilder
extend Forwardable
def_delegators :@query, :projections, :join_sources, :orders
attr_reader :book, :genre, :author
# @param query [Arel::SelectManager] an ARel AST
# @return [QueryBuilder] an initialized QueryBuilder
def initialize(query = nil)
@book = Book.arel_table
@genre = Genre.arel_table
@author = Author.arel_table
super(query || @book)
end
# @return [QueryBuilder] a new QueryBuilder instance
# with book columns projection
def with_book_details
reflect query.
project(
pick_one(book[:title]).as("title"),
pick_one(book[:isbn]).as("isbn"),
pick_one(book[:format]).as("format"),
safe_sum(book[:pages]).as("pages"),
round_avg(book[:rating]).as("rating")
)
end
# @return [QueryBuilder] a new QueryBuilder instance
# filtering on read books
def only_read_books
reflect query.where(book[:status].eq 2)
end
# @return [QueryBuilder] a new QueryBuilder instance
# with author columns projection
def with_author_details
reflect query.
join(author).on(author[:id].eq book[:author_id]).
project(author[:name].maximum.as("author"))
end
# @return [QueryBuilder] a new QueryBuilder instance
# with genre columns projection
def with_genre_details
reflect query.
join(genre).on(genre[:id].eq book[:genre_id]).
project(pick_one(genre[:label]).as("label"))
end
# @return [QueryBuilder] a new QueryBuilder instance
# with rank projection
# and grouped by author and then by book
def grouped_by_author_and_book
reflect query.
project(grouping(grouping_elements).as("rank")).
group(grouping_sets(grouping_elements))
end
# @return [Arel::Nodes::RollUp] the roll up grouping sets
def grouping_books
grouping_sets(grouping_elements)
end
# @return [QueryBuilder] a new QueryBuilder instance
# ordered by author name and then by book title
def ordered_by_author_name_and_book_title
reflect query.order("author, title, rank")
end
protected
# @return [Array<Arel::Attributes::Attribute>] the ARel attributes to group by
def grouping_elements
[author[:id], book[:id]]
end
end
Toutes nos méthodes font appel à reflect que nous avions déclaré dans
QueryBuilder afin de pouvoir les chaîner entre elles. Du reste, on utilise
ARel tel que vous avez déjà eu l’occasion de l’appréhender à la lecture de
notre précédent article cité
ci-dessus.
Il ne nous reste plus qu’à composer notre requête à l’aide de la classe
BookStatQueryBuilder que nous venons de créer.
class BookStat
# @return [ActiveRecord::Relation] the queried data
def self.query
query_builder = BookStatQueryBuilder.new.
only_read_books.
with_book_details.
with_author_details.
with_genre_details.
grouped_by_author_and_book.
ordered_by_author_name_and_book_title
Book.
select(query_builder.projections).
joins(query_builder.join_sources).
where(query_builder.where_clause).
group(query_builder.grouping_books).
order(query_builder.orders)
end
end
À présent, si nous souhaitons connaître le nombre de lignes retournées par une
telle requête — mais en prenant soin de ne pas comptabiliser les lignes de
sous-totaux — nous pouvons ré-exploiter notre classe BookStatQueryBuilder en
composant notre requête un peu différemment.
class BookStat
# @return [Integer] the number of queried data rows
def self.count_query
query_builder = BookStatQueryBuilder.new.
only_read_books.
with_book_details.
with_author_details.
with_genre_details
Book.
select(Arel.star).
joins(query_builder.join_sources).
where(query_builder.where_clause).
count
end
end
Nous aurions pu pousser le vice un peu plus loin en utilisant GROUPING avec la
fonction conditionnelle CASE pour retourner des valeurs différentes selon que
l’on est sur une ligne de statistiques d’un auteur ou d’un livre.
SELECT CASE GROUPING(authors.id, books.id)
WHEN 0 THEN MAX(books.title)
ELSE NULL
END AS title;
Avec une telle formulation, les lignes correspondant à un livre (celles avec un
rang à 0) se verront affecter le titre du livre, tandis que les autres auront
une valeur nulle. L’idée étant bien évidemment de généraliser ceci à toutes les
colonnes issues des tables books et genres.
Pour arriver à un tel résultat, il nous suffit simplement de réécrire notre
méthode pick_one de la manière suivante.
class BookStatQueryBuilder < StatQueryBuilder
include Arel::Nodes
# @param field [Arel::Attributes::Attribute] an ARel table field
# @return [Arel::Nodes::Maximum] max value for the given field
def pick_one(field)
Case.new(grouping(grouping_elements)).when(0).then(field.maximum).else(nil)
end
end
Ce qui donnera en définitive :
+------------------------+---------------+----------+---------+----------+------------------+---------+--------+
| title | isbn | format | pages | rating | author | label | rank |
|------------------------+---------------+----------+---------+----------+------------------+---------+--------|
| La Horde du Contrevent | 9782070449064 | 0 | 1,392 | 4 | Damasio, Alain | Fantasy | 0 |
| La Zone du Dehors | 9782917157114 | 0 | 492 | 3 | Damasio, Alain | SF | 0 |
| <null> | <null> | <null> | 1,884 | 4 | Damasio, Alain | <null> | 1 |
| Strata | 9780552133258 | 0 | 288 | 4 | Pratchett, Terry | SF | 0 |
| The Color of Magic | 9780062225672 | 0 | 288 | 3 | Pratchett, Terry | Fantasy | 0 |
| <null> | <null> | <null> | 576 | 4 | Pratchett, Terry | <null> | 1 |
| <null> | <null> | <null> | 2,460 | 4 | Pratchett, Terry | <null> | 3 |
+------------------------+---------------+----------+---------+----------+------------------+---------+--------+
En conclusion, vous devriez avoir une meilleure idée des abstractions que l’on peut utiliser pour éviter de manipuler directement les objets ActiveRecord que fournit Rails. ActiveRecord n’offre qu’une abstraction supplémentaire pour manipuler directement des modèles à la fin de l’opération ; ce qui peut être très pratique dans certains cas mais qui devient vite un gouffre à performance quand on manipule beaucoup de données.
Dans tous les cas, apprendre ARel vous permettra de mieux comprendre ActiveRecord, de la même façon qu’apprendre SQL vous permettra de mieux comprendre ARel. Chacun a ses forces et ses faiblesses qu’il convient de connaître pour pouvoir les déployer au moment opportun.
L’équipe Synbioz.
Libres d’être ensemble.
